In my last post I introduced a couple of concepts from the channel theory of Jeremy Seligman and Jon Barwise. In this post I would like to continue that introduction.
To review, channel theory is intended to help us understand information flows of the following sort: a‘s being F carries the information that b is G. For example, we might want a general framework in which understand how a piece of fruit’s bitterness may carry the information that it is toxic, or how a mountain side’s having a particular distribution of flora can carry information about the local micro-climate, or how a war leader’s generous gift-giving may carry information about the success of a recent campaign, or the sighting of a gull can carry the information that land is near. In a previous post, we asked how position of various participants in a fono might forecast information about the political events of the day. One would hope that such a framework may even illuminate how an incident in which a person gets sick and dies may be perceived to carry the information that there is a sorcerer who is responsible for this misfortune.
In my last post, I introduced a simple sort of data structure called a classification. A classification simply links particulars to types. But as my examples above were intended to show, classifications are not only intended to model ‘categorical’ data, as usually construed.
Def 1. A classification is a triple A = 
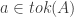
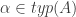



One might remark that a classification is not much more than a table whose attributes have only two possible value, a sort of degenerate relational database. However, unlike a record/row in a relational database, channel theory treats each token as a first-class object. Relational databases require keys to guarantee that each tuple is unique, and key constraints to model relationships between records in tables. By treating tokens as first class objects, we may model relationships using an infomorphism:
Def 2. Let 

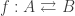
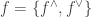
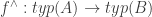

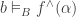
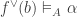
An infomorphism is more general than an isomorphism between classifications, i.e. an isomorphism is a special case of an infomorphism. For example, an infomorphism 
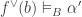
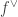
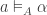
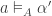
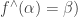
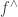
It is actually rather difficult to find infomorphisms between arbitrary classifications. In many cases there will be none. If it were too easy, then the morphism would not be particularly meaningful. Too stringent and then it would not be very applicable. However, two classifications may be joined in a fairly standard way.For example, we can add them together:
Def 3. Given two classifications A and B, the sum of A and B is the classification A+B such that:
1. 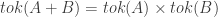
2. 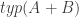


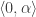



3. for each token 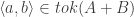
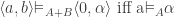

Remark. For any two classifications A and B there exist infomorphisms 
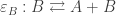
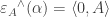

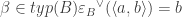
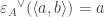
To see how this is useful, we turn now to Barwise and Seligman’s notion of an information channel.
Def 4. A channel C is an indexed family of infomorphisms 
As it turns out, in a result known as the Universal Mapping Property of Sums, given a binary channel C = 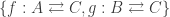

The result is general and can be applied to arbitrary channels and sums.
I still haven’t exactly shown how this is useful. To do that we introduce some inference rule that can be used to reason from the periphery to the core and back again in the channel.
A sequent 


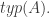
Def 5. Given a classification 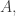


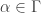

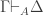
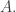
Barwise and Seligman introduce two inference rules: f-Intro and f-Elim. Given an infomorphism from a classification A to a classification C, 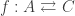


The two rules have different properties. f-Intro preserves validity, f-Elim does not preserve validity; f-Intro fails to preserve invalidity, but f-Elim fails to preserve invalidity. f-Elim is however valid precisely for those tokens in A for which there is a token b of B mapping onto A by the infomorphism f.
Suppose then that we have a channel. At the core is a classification of flashlights, and and at the periphery are classifications of bulbs and switches. We can take a sum of the classifications of bulbs and switches. We know that there are infomorphisms from these classifications to the sum (and so this too makes up a channel), and using f-Intro, we know that any sequents of the classifications of bulbs and switches will still hold in the sum classifications: bulbs + switches. But note that the classification bulbs + switches, since it connects every bulb and switch token, any sequents that might properly hold between bulbs and switches will not hold in the sum classification. Similarly, all the sequents holding in the classification bulbs + switches will hold in the core of the flashlight channel. However, there will be constraints in the core (namely those holding between bulbs and switches) not holding in the sum classification bulbs + switches.
In brief: suppose that we know that a particular switch is in the On position, and that it is a constraint of switches that a switch being in the On position precludes it being in the Off position. We can project this constraint into the core of the flashlight channel reliably. But in the channel additional constraints hold (the ones we are interested in). Suppose that in the core of the channel, there is a constraint that if a switch is On in a flashlight then the bulb is Lit in the flashlight We would like to know that because *this* switch is in the On position, that a particular bulb will be Lit. How can we do it? Using f-Elim we can pull back the constraint of the core to the sum classification. But note, that this constraint is *not valid* in the sum-classification. But it is not valid for precisely those bulbs that are not connected in the channel. In this way, we can reason from local information to a distant component of a system, but in so doing, we lose the guarantee that our reasoning is valid, and we lose the guarantee that it is sound.
[1] Barwise, Jon, and Jerry Seligman. 1997. Information Flow: The Logic of Distributed Systems. Cambridge tracts in theoretical computer science 44. Cambridge: Cambridge University Press.
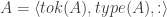 such that for every token
such that for every token  if and only if
if and only if  if and only if
if and only if 
